Insertion Sort

Insertion Sort: Pseudocode
|
|
Insertion Sort: Complexity analysis
insertion sort has a best-case running time of $$\theta{(n)}$$ (pronounced “theta of n”).
insertion sort has an average and worst-case running time of $$\theta{(n^2)}$$ (pronounced “theta of n-squared”).
Insertion Sort: Advantages
Efficient for (quite) small data sets
Stable; i.e., does not change the relative order of elements with equal keys
In-place; i.e., only requires a constant amount O(1) of additional memory space
Merge Sort

Merge Sort: Pseudocode
|
|
|
|
Merge Sort: Complexity analysis
merge sort has an average and worst-case running time of $\theta(n \lg n)$
merge sort’s worst-case space complexity $\theta(n)$
Merge Sort: Advantages
Merge sort is more efficient than quicksort for some types of lists if the data to be sorted can only be efficiently accessed sequentially.
Unlike some (efficient) implementations of quicksort, merge sort is a stable sort.
Merge sort is often the best choice for sorting a linked list: in this situation it is relatively easy to implement a merge sort in such a way that it requires only $\theta(1)$ extra space, and the slow random-access performance of a linked list makes some other algorithms (such as quicksort) perform poorly, and others (such as heapsort) completely impossible.
Bubble Sort

Bubble Sort: Pseudocode
|
|
Bubble Sort: Complexity analysis
Bubble sort has a worst-case and average complexity of $O(n^2)$
Quicksort
Quicksort: Pseudocode
|
|
|
|
Quicksort: Complexity analysis
The quicksort algorithm has a worst-case running time of $\theta(n^2)$.
Despite this slow worst-case running time, quicksort is often the best practical choice for sorting because it is remarkably efficient on the average: its expected running time is $\theta(n \lg n)$.
The running time of quicksort depends on whether the partitioning is balanced or unbalanced, which in turn depends on which elements are used for partitioning. If the partitioning is balanced, the algorithm runs asymptotically as fast as merge sort. If the partitioning is unbalanced, however, it can run asymptotically as slowly as insertion sort.
The average-case running time of quicksort is much closer to the best case than to the worst case.
In fact, any split of constant proportionality yields a recursion tree of depth $\theta(n \lg n)$, where the cost at each level is $O(n)$. The running time is therefore $\theta(n \lg n)$ whenever the split has constant proportionality.
Quicksort: Scenses
It has the advantage of sorting in place.
Moreover, the $\theta(n^2)$ running time occurs when the input array is already completely sorted—a common situation in which insertion sort runs in $O(n)$ time.
A randomized version of quicksort
Randomized quicksort: Pseudocode
|
|
|
|
Randomized quicksort: Complexity analysis
the (worst-case) running time of quicksort is $\theta(n^2)$.
the expected running time of RANDOMIZED -QUICKSORT is $O(n \lg n)$.
Counting Sort
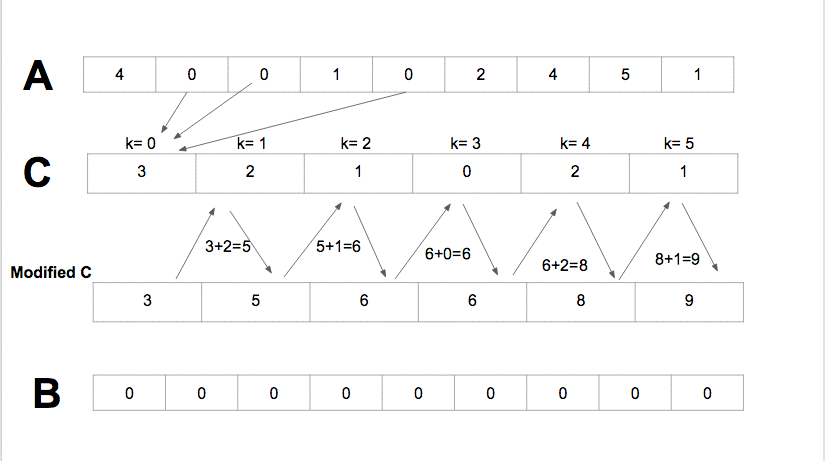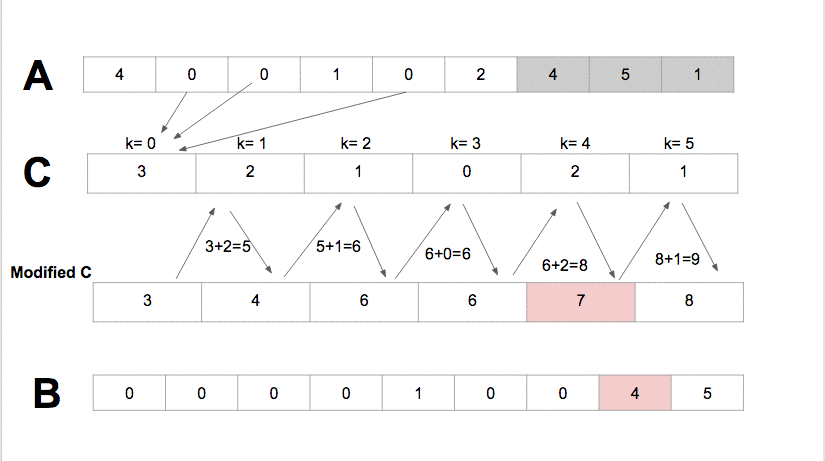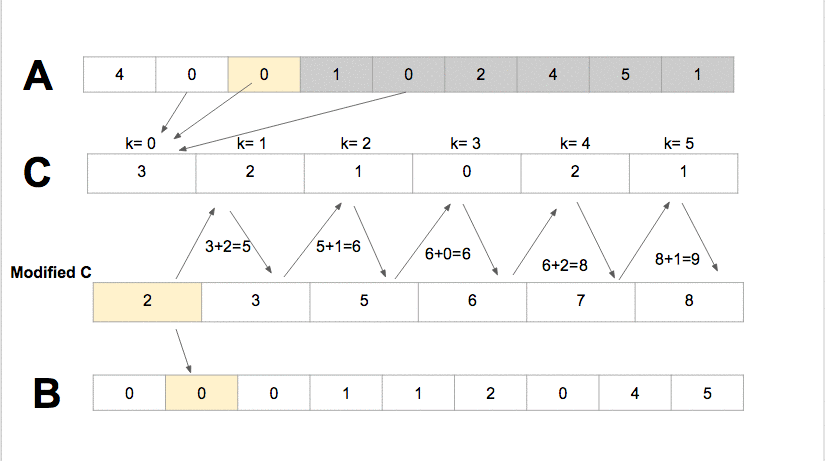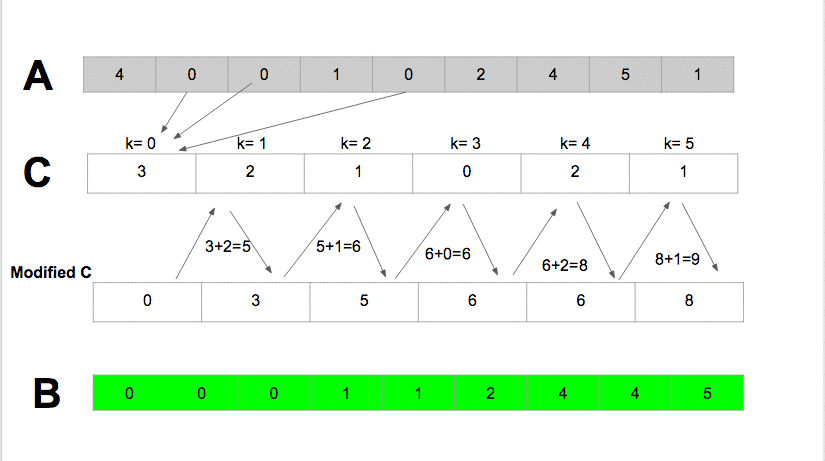
Counting Sort: Pseudocode
|
|
Counting Sort: Complexity analysis
Counting sort has time complexity of $O(k + n)$
Because it uses arrays of length $k + 1$ and $n$, the total space usage of the algorithm is also $O(n + k)$.
Counting Sort: Scenes
it is an integer sorting algorithm
it is a stable sort.
Radix Sort
Radix Sort: Pseudocode
|
|
Radix Sort: Complexity analysis
Radix sort operates in $O(nw)$ time, where $n$ is the number of keys, and $w$ is the key length.
Radix Sort: Scenes
Moreover, the version of radix sort that uses counting sort as the intermediate stable sort does not sort in place, which many of the ‚.n lg n/-time comparison sorts do. Thus, when primary memory storage is at a premium, we might prefer an in-place algorithm such as quicksort.
Bucket Sort
Bucket Sort: Pseudocode
|
|
Bucket Sort: Complexity analysis
Bucket sort has an average complexity of $\theta(n)$
Bucket sort has a worst-cast complexity of $\theta(n^2)$
Summarizes the sorting algorithms
| Algorithms | Worst-cast running time | Average-case / expected running time |
|---|---|---|
| Insertion sort | $\theta(n^2)$ | $\theta(n^2)$ |
| Merge sort | $\theta(n \lg n)$ | $\theta(n \lg n)$ |
| Heapsort | $\theta(n \lg n)$ | — |
| Quicksort | $\theta(n^2)$ | $\theta(n \lg n)$ (expected) |
| Counting sort | $\theta(n+k)$ | $\theta(n+k)$ |
| Radix sort | $\theta(d(n+k))$ | $\theta(d(n+k))$ |
| Bucket sort | $\theta(n^2)$ | $\theta(n)$ |