English
电脑/手机换成英文系统,所有软件一律调成英文界面,不要用QQ,要用QQ International,不要用微信,要用WeChat 挂代理,远离百度/CSDN,有问题查官方文档,上爆栈,没事水一下quora/reddit,订阅国外牛人的博客,加入感兴趣技术的官方mailing list 看书能找到影印版/原版就坚决不看翻译版
另外edx公开课视频播放可以变速播放,还有字幕,听力不行可以先从0.5x听起
Programming
前2年只能用python, scheme或者c(三选一)。后2年可以用java
前2年学完算法全系列,数据结构和算法,离散数学,概率论的思维。接下来2年好好学网络,操作系统,数据库,安全。人工智能,机器学习,高等计算法,图形学选修。
第5年做大项目
机器学习,分布式系统,并行计算是驱动行业的科技
Programming Languages
用python写代码目前看来效率是最高的,比Go还高,如果对性能不重视的场合,肯定首选python。Go开发效率很高,写并发程序超级省心,和linux系统结合也比java好,部署简单。长期看来,一直依赖的c/c++/Java/Python可能会变成c/go/python,完全能实现一样的功能和性能,而且更加高效。 c++/java都不是很感冒,对团队合作来说,任何除了标准之外还需要强制定义一堆编程规范的语言都是蹩脚的。语言本身的特性是否健全对我来说不是最重要,能否持续高效的产出低bug少坑的工程代码才是我考虑的最多的因素。
当你期望把你做的库移植到很多其他语言的时候,C更具优势。你也可以底层用C++实现,不过做一层C包装也是有必要的。
要问为什么,一门语言实现C FFI的难度和C++ FFI的难度显然不在一个数量级。。 C语言编译后有一定的二进制兼容性。C库很容易被其他语言或工具调用,问题不大。C++就是一坨翔,编译后你连函数名都找不到。
作者:gashero 链接:https://www.zhihu.com/question/60312340/answer/240462043 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
我的建议稍长,如下几点: 1、能用python解决的事情优先用python 2、C要学好,语言所有功能,好在也没多点内容,比python功能集略多而已 3、能基本读懂常见的C++代码 4、能使用基本的C++语法编程,如继承和重载,达到使用常用第三方C++库不受限制即可 5、学会常用C标准库,如字符串、文件、线程 达到如上所说的标准并不会花多少时间,也许还不到通读C++ Primer的一半。随后你的精力应该花在有用的事情上,比如各种工作上用到的库,比如调试,比如算法。 C++设计之初是希望兼顾C级别的性能、对C的兼容性、对大型工程的抽象支持能力。但这几个方向做的都不太好。性能上,论运行性能还可以,编译速度就不敢恭维了。对C的兼容性就比较呵呵了,君不见各平台动态库的实现里C++导出符号表的复杂程度。只能说能兼容,但特别拧巴。对大型工程的抽象则是个彻底的失败。80年代后的各类语言在动态性等方面发展的都不错,但C++却受限于不忍放弃前两者,实现的特别恶心。比如C++里的模版,为的是让各种方法不再受限于强类型的麻烦。但方便性是远远比不上类型与变量值绑定的。
C++里的很多特性,是给程序员用来设计类库的,而不是用来写应用程序的。这些特性对绝大多数程序员真的大概率一辈子都用不上,却要被一个“熟练”、“精通”的形容词驱赶着浪费时间。
所以我如上多条建议的核心就是,不要把精力浪费在C++上,能确保基础使用即可。其他能避开的尽量python+C搞定。否则就以C++那么多人为制造出来的复杂性,可以耗尽你近乎无限的时间,同时对工作并没有什么卵用。 我个人平时主要就是遵循如上规则。单片机程序跑不了用C,上位机程序和其他代码基本都是用python,性能相关的会用python的C扩展搞定。C++则是2004年拿到软件设计师后就很少使用了。即便是用OpenCV的C++版和python版时也不耽误。
python, scheme或者c
java
Golang
packages
bytes
crypto md5 rand
encoding/json errors flag fmt html/template image
io io/ioutil log math big bits cmplx rand mime multipart quotedprintable net/http cgi cookiejar fcgi httptest httptrace httputil pprof mail rpc jsonrpc smtp textproto url os exec signal user path filepath plugin reflect regexp syntax runtime cgo debug msan pprof race trace sort strconv strings sync atomic syscall js testing iotest quick text scanner tabwriter template parse time unicode utf16 utf8 unsafe Other packages Sub-repositories These packages are part of the Go Project but outside the main Go tree. They are developed under looser compatibility requirements than the Go core. Install them with “go get”.
benchmarks — benchmarks to measure Go as it is developed. blog — blog.golang.org’s implementation. build — build.golang.org’s implementation. crypto — additional cryptography packages. debug — an experimental debugger for Go. image — additional imaging packages. mobile — experimental support for Go on mobile platforms. net — additional networking packages. perf — packages and tools for performance measurement, storage, and analysis. review — a tool for working with Gerrit code reviews. sync — additional concurrency primitives. sys — packages for making system calls. text — packages for working with text. time — additional time packages. tools — godoc, goimports, gorename, and other tools. tour — tour.golang.org’s implementation. exp — experimental and deprecated packages (handle with care; may change without warning). Community These services can help you find Open Source packages provided by the community.
GoDoc - a package index and search engine. Go Search - a code search engine. Projects at the Go Wiki - a curated list of Go projects.
packages2
| heap |
|---|
| list |
| Name |
|---|
| archive |
| tar |
| zip |
| bufio |
| builtin |
| bytes |
| compress |
| bzip2 |
| flate |
| gzip |
| lzw |
| zlib |
| container |
| heap |
| list |
| ring |
| context |
| crypto |
| aes |
| cipher |
| des |
| dsa |
| ecdsa |
| elliptic |
| hmac |
| md5 |
| rand |
| rc4 |
| rsa |
| sha1 |
| sha256 |
| sha512 |
| subtle |
| tls |
| x509 |
| pkix |
| database |
| sql |
| driver |
| debug |
| dwarf |
| elf |
| gosym |
| macho |
| pe |
| plan9obj |
| encoding |
| ascii85 |
| asn1 |
| base32 |
| base64 |
| binary |
| csv |
| gob |
| hex |
| json |
| pem |
| xml |
| errors |
| expvar |
| flag |
| fmt |
| go |
| ast |
| build |
| constant |
| doc |
| format |
| importer |
| parser |
| printer |
| scanner |
| token |
| types |
| hash |
| adler32 |
| crc32 |
| crc64 |
| fnv |
| html |
| template |
| image |
| color |
| palette |
| draw |
| gif |
| jpeg |
| png |
| index |
| suffixarray |
| io |
| ioutil |
| log |
| syslog |
| math |
| big |
| bits |
| cmplx |
| rand |
| mime |
| multipart |
| quotedprintable |
| net |
| http |
| cgi |
| cookiejar |
| fcgi |
| httptest |
| httptrace |
| httputil |
| pprof |
| rpc |
| jsonrpc |
| smtp |
| textproto |
| url |
| os |
| exec |
| signal |
| user |
| path |
| filepath |
| plugin |
| reflect |
| regexp |
| syntax |
| runtime |
| cgo |
| debug |
| msan |
| pprof |
| race |
| trace |
| sort |
| strconv |
| strings |
| sync |
| atomic |
| syscall |
| js |
| testing |
| iotest |
| quick |
| text |
| scanner |
| tabwriter |
| template |
| parse |
| time |
| unicode |
| utf16 |
| utf8 |
| unsafe |
Other packages **## Sub-repositories
** These packages are part of the Go Project but outside the main Go tree. They are developed under looser compatibility requirements than the Go core. Install them with “go get”.
- benchmarks — benchmarks to measure Go as it is developed.
- blog — blog.golang.org’s implementation.
- build — build.golang.org’s implementation.
- crypto — additional cryptography packages.
- debug — an experimental debugger for Go.
- image — additional imaging packages.
- mobile — experimental support for Go on mobile platforms.
- net — additional networking packages.
- perf — packages and tools for performance measurement, storage, and analysis.
- review — a tool for working with Gerrit code reviews.
- sync — additional concurrency primitives.
- sys — packages for making system calls.
- text — packages for working with text.
- time — additional time packages.
- tools — godoc, goimports, gorename, and other tools.
- tour — tour.golang.org’s implementation.
- exp — experimental and deprecated packages (handle with care; may change without warning).
**## Community
** These services can help you find Open Source packages provided by the community.
- GoDoc - a package index and search engine.
- Go Search - a code search engine.
- Projects at the Go Wiki - a curated list of Go projects.
Build version go1.12. Except as noted, the content of this page is licensed under the Creative Commons Attribution 3.0 License, and code is licensed under a BSD license. Terms of Service | Privacy Policy
packages3
heap list
database sql
debug
encoding json xml errors
fmt go ast build constant doc format importer parser printer scanner token types hash adler32 crc32 crc64 fnv html template image color palette draw gif jpeg png index suffixarray io ioutil log syslog math big bits cmplx rand mime multipart quotedprintable net http cgi cookiejar fcgi httptest httptrace httputil pprof mail rpc jsonrpc smtp textproto url os exec signal user path filepath plugin reflect regexp syntax runtime cgo debug msan pprof race trace sort strconv strings sync atomic syscall js testing iotest quick text scanner tabwriter template parse time unicode utf16 utf8 unsafe Other packages Sub-repositories These packages are part of the Go Project but outside the main Go tree. They are developed under looser compatibility requirements than the Go core. Install them with “go get”.
benchmarks — benchmarks to measure Go as it is developed. blog — blog.golang.org’s implementation. build — build.golang.org’s implementation. crypto — additional cryptography packages. debug — an experimental debugger for Go. image — additional imaging packages. mobile — experimental support for Go on mobile platforms. net — additional networking packages. perf — packages and tools for performance measurement, storage, and analysis. review — a tool for working with Gerrit code reviews. sync — additional concurrency primitives. sys — packages for making system calls. text — packages for working with text. time — additional time packages. tools — godoc, goimports, gorename, and other tools. tour — tour.golang.org’s implementation. exp — experimental and deprecated packages (handle with care; may change without warning). Community These services can help you find Open Source packages provided by the community.
GoDoc - a package index and search engine. Go Search - a code search engine. Projects at the Go Wiki - a curated list of Go projects.
packages4
| Name |
|---|
| archive |
| tar |
| zip |
| bufio |
| builtin |
| bytes |
| compress |
| bzip2 |
| flate |
| gzip |
| lzw |
| zlib |
| container |
| heap |
| list |
| ring |
| context |
| crypto |
| aes |
| cipher |
| des |
| dsa |
| ecdsa |
| elliptic |
| hmac |
| md5 |
| rand |
| rc4 |
| rsa |
| sha1 |
| sha256 |
| sha512 |
| subtle |
| tls |
| x509 |
| pkix |
| database |
| sql |
| driver |
| debug |
| dwarf |
| elf |
| gosym |
| macho |
| pe |
| plan9obj |
| encoding |
| ascii85 |
| asn1 |
| base32 |
| base64 |
| binary |
| csv |
| gob |
| hex |
| json |
| pem |
| xml |
| errors |
| expvar |
| flag |
| fmt |
| go |
| ast |
| build |
| constant |
| doc |
| format |
| importer |
| parser |
| printer |
| scanner |
| token |
| types |
| hash |
| adler32 |
| crc32 |
| crc64 |
| fnv |
| html |
| template |
| image |
| color |
| palette |
| draw |
| gif |
| jpeg |
| png |
| index |
| suffixarray |
| io |
| ioutil |
| log |
| syslog |
| math |
| big |
| bits |
| cmplx |
| rand |
| mime |
| multipart |
| quotedprintable |
| net |
| http |
| cgi |
| cookiejar |
| fcgi |
| httptest |
| httptrace |
| httputil |
| pprof |
| rpc |
| jsonrpc |
| smtp |
| textproto |
| url |
| os |
| exec |
| signal |
| user |
| path |
| filepath |
| plugin |
| reflect |
| regexp |
| syntax |
| runtime |
| cgo |
| debug |
| msan |
| pprof |
| race |
| trace |
| sort |
| strconv |
| strings |
| sync |
| atomic |
| syscall |
| js |
| testing |
| iotest |
| quick |
| text |
| scanner |
| tabwriter |
| template |
| parse |
| time |
| unicode |
| utf16 |
| utf8 |
| unsafe |
Other packages **## Sub-repositories
** These packages are part of the Go Project but outside the main Go tree. They are developed under looser compatibility requirements than the Go core. Install them with “go get”.
- benchmarks — benchmarks to measure Go as it is developed.
- blog — blog.golang.org’s implementation.
- build — build.golang.org’s implementation.
- crypto — additional cryptography packages.
- debug — an experimental debugger for Go.
- image — additional imaging packages.
- mobile — experimental support for Go on mobile platforms.
- net — additional networking packages.
- perf — packages and tools for performance measurement, storage, and analysis.
- review — a tool for working with Gerrit code reviews.
- sync — additional concurrency primitives.
- sys — packages for making system calls.
- text — packages for working with text.
- time — additional time packages.
- tools — godoc, goimports, gorename, and other tools.
- tour — tour.golang.org’s implementation.
- exp — experimental and deprecated packages (handle with care; may change without warning).
**## Community
** These services can help you find Open Source packages provided by the community.
- GoDoc - a package index and search engine.
- Go Search - a code search engine.
- Projects at the Go Wiki - a curated list of Go projects.
in action
Copy
Command line start web service https://github.com/photoprism/photoprism/blob/develop/internal/commands/start.go
Initialize values from yaml config file Connect to database MigrateDB https://github.com/photoprism/photoprism/blob/develop/internal/context/config.go
App run https://github.com/photoprism/photoprism/blob/develop/internal/server/server.go
Like api v1 https://github.com/photoprism/photoprism/blob/develop/internal/server/routes.go
Here is view set and routes, It would be better to separate routes and view set https://github.com/photoprism/photoprism/blob/develop/internal/api/photos.go
This can imitate https://github.com/gothinkster/golang-gin-realworld-example-app/blob/master/articles/routers.go
https://github.com/photoprism/photoprism/tree/develop/internal/models
Serializers and validators https://github.com/gothinkster/golang-gin-realworld-example-app/blob/master/articles/serializers.go
https://github.com/gothinkster/golang-gin-realworld-example-app/blob/master/articles/validators.go
Golang在SmartX的实践 https://cloud.tencent.com/developer/news/267238
最后采用photoprism和course_discovery的实践方式
https://github.com/photoprism/photoprism/blob/develop/internal/tidb/init.go
https://github.com/gothinkster/golang-gin-realworld-example-app
write as course_discovery
https://github.com/EDDYCJY/go-gin-example
https://github.com/b3log/pipe/blob/master/controller/console/userctl.go
AddUserToBlog
评价
我们算法部门原来基于nginx/c++开发的服务模块,单机12kqps,cpu上不去。我开发了一个golang的,轻松跑满cpu,单机40kqps,开发效率还比你高好几倍。这谁还敢来歪歪?不服来战啊。
主要用来做http服务,就是微服务,grpc,rest api那一套 做云计算的(paas ,k8s,docker )也在使用go 写系统工具:据说 Google 内部已经把大量 Python 写的工具迁移成 Go 的了
包管理
**Gopm **包管理器,下载再也不用翻墙
https://shockerli.net/post/go-get-golang-org-x-solution/
export GO111MODULE=on export GOPROXY=https://goproxy.io
cd $GOPATH/src mkdir -p github.com/user/repo
cd github.com/user/repo go mod init
go get
Language reference
https://github.com/golang/go/wiki/Well-known-struct-tags
http://golang.org/pkg/reflect/#StructTag
other
https://blog.csdn.net/linux_player_c/article/details/81869810
https://www.jianshu.com/p/d7fdc77b5324
还需要技能
我还需要的技能:
- 大型分布式系统设计与开发
- docker
- k8s
- bash
- mongodb
- 微服务架构
- python flink
- python spark streaming
- tcp/ip编程
- MQ
C++
看你做什么了。花一天把 fork, exec, mknod, pipe, open, close, read, write, socket, bind, listen, accept, connect, epoll_, signal, pthread_, boost.coroutine 写点样例熟悉一遍,有病治病,没病强身。
工具的话知道gcc/clang就够了,剩下的以后再学。
把最基本的几个函数看一下:socket, connect, bind, listen, accept, read, write, epoll; 另外就是std::thread, std::future, std::mutex什么的。不是什么大事查查文档,google点样例就行了,看什么书。。。
《unix环境高级编程》,老老实实看完重点章节,敲敲示例代码
1,3,4;7-16(重点看),一般每一章前三分之二节比较重要,后面的大概看看
最合适的书是the linux program interface。apue有点过时了。c++11可以简化很多跨平台的问题。你得花几个星期甚至更长时间研究一下gcc和ld的参数以及具体含义。大部分都和linker&loader有关。
用clion
为什么非要看书呢?去把c++11的wikipedia翻一翻,查一查http://cppreference.com上的介绍,再写点代码实验实验,私以为已经可以了。
不要看任何中文材料。
不要看任何中文材料。
不要看任何中文材料。
至于C,忘得越干净越好。你要是学的是中国大学里的C,不忘掉反而有害。
不要看书。
自己实现一个标准的std::vector。
不知道怎么写就看标准库怎么写的。
不知道标准库写的什么意思就查http://cppreference.com。
http://cppreference.com看不懂就看standard。
standard看不懂就去so上面问,注意显示你已经做过功课了。
专心全职累计写1个月(可以不连续),把个vector写出来。
下一步写std::shared_ptr。用虚函数。
这两个写完你工作的C++部分就够了。工作中用到的那些pattern(譬如oop)一点就透。
如果工作不用,那你学了干嘛?
我不觉得这很简单,但我觉得这是最有效的学习方式。
c++ primer / ubuntu / vim / Makefile
算法团队大多用c++,而且对编程技能要求不是特别高。不过么……总之你可以来试试。
把常用算法和数据结构实现一遍。
同步共享变量还好,很容易就能发现然后用互斥锁解 可是竞争感觉平时写代码很不容易察觉啊?
例如写个 JSON 解析器、正则引擎、软件光栅化、键值对存储等等吧。
蓝色
作者:蓝色 链接:https://www.zhihu.com/question/20138166/answer/92851495
来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
C++应用太宽泛,我认为这时候需要确定到底想要了解什么,然后再来看,没有目的的漫看,收获总是甚微的。如同在工作的时候,不以任务** / 解决 BUG 的目的去阅读项目代码,总是缓慢的想睡觉。
**
所以,我认为应该首先想我作为C++的初学者(也就是学完了C++语法以后),我接下来想完成些什么呢。譬如说,我要写一个小游戏,就俄罗斯方块好了,但是我不知道怎么写,那这时候我就应该去找写的好的俄罗斯方块代码来看,而不是大而全的STL,网络库,图像库等。因为这时候我的目的是做一个俄罗斯方块游戏,而作为最初级的C++学习者,我只会一些语法,还不知道怎么用,正好可以把感兴趣的东西和这个游戏结合起来。
**
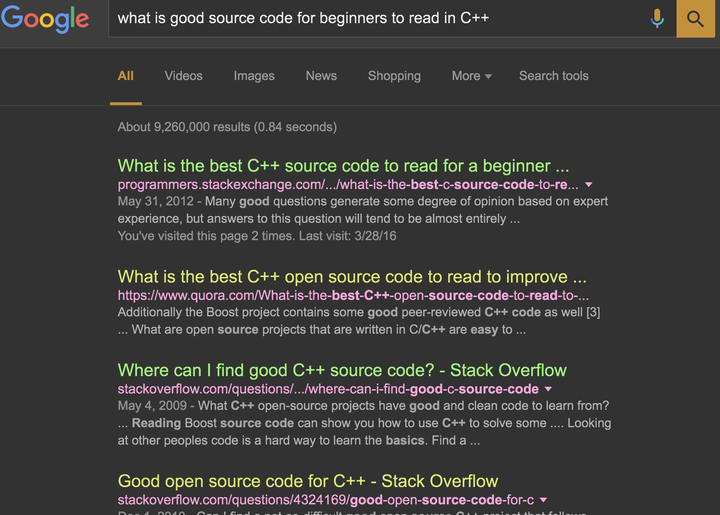
然后直接Google C++ game source code (怎么Google**也是一大技巧)
<img src=“https://pic1.zhimg.com/50/1b199b87ef2c2475ac7a97c8c2fb2c1f_hd.jpg" data-rawwidth=“1786” data-rawheight=“1120” class=“origin_image zh-lightbox-thumb” width=“1786” data-original=“https://pic1.zhimg.com/1b199b87ef2c2475ac7a97c8c2fb2c1f_r.jpg"&gt;

{kind=link}
{kind=link}
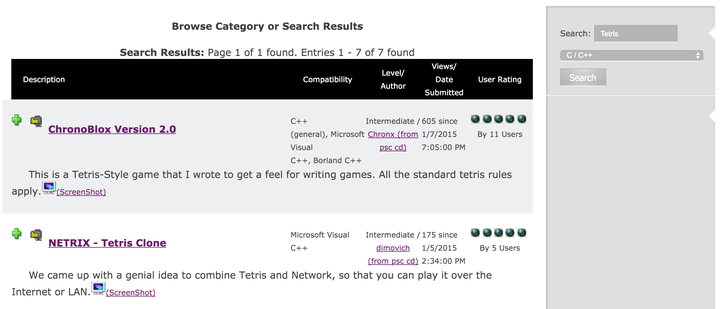
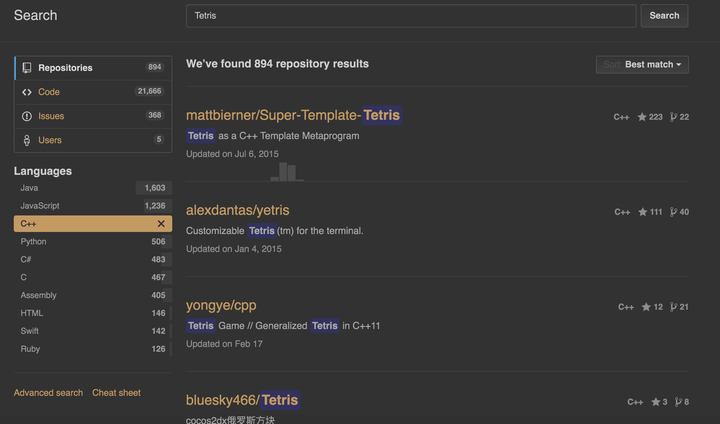
然后直接就看到第一个了,点击进去以后,搜索俄罗斯方块Tetris
<img src=“https://pic1.zhimg.com/50/f683dc184d191011ca52d83bd465791c_hd.jpg" data-rawwidth=“2416” data-rawheight=“1038” class=“origin_image zh-lightbox-thumb” width=“2416” data-original=“https://pic1.zhimg.com/f683dc184d191011ca52d83bd465791c_r.jpg"&gt;

{kind=link}
{kind=link}
然后点击看看每一个项目的大致效果,先外表吸引人再决定看下去,比如第一个
<img src=“https://pic2.zhimg.com/50/ec8c84a7064818b2bd72d4bb66b29f6f_hd.jpg" data-rawwidth=“1576” data-rawheight=“976” class=“origin_image zh-lightbox-thumb” width=“1576” data-original=“https://pic2.zhimg.com/ec8c84a7064818b2bd72d4bb66b29f6f_r.jpg"&gt;

{kind=link}
{kind=link}
看起来还不错,于是就可以下下来来研究了。这时候初学的时候,最差的感觉是如何把代码做成一个项目,至于设计模式,是不是够
**## C++er
**## 等,这时候可能稍微比如何把代码做成一个项目差一点点。写代码的一大驱动力就是:成就感!做成了才有比较大的成就感,才有驱动力让代码变得更好。所以,现在看到这么好的东西就有第一驱动力去阅读她,去修改她,去完成的更好。没有动力,怎么行呢。 **##
**
当然,这是
**## 的方式,还有一个就是在最大的同性交友网站 **## GitHub
**## ,你要做什么也可以搜索,比如 **## Tetris
**
<img src=“https://pic1.zhimg.com/50/85493acdd4f38ae344f3381d60b4d19b_hd.jpg" data-rawwidth=“1982” data-rawheight=“626” class=“origin_image zh-lightbox-thumb” width=“1982” data-original=“https://pic1.zhimg.com/85493acdd4f38ae344f3381d60b4d19b_r.jpg"&gt;

{kind=link}
{kind=link}
<img src=“https://pic2.zhimg.com/50/80e327d62bf70d7661182d44d08c6c7e_hd.jpg" data-rawwidth=“2090” data-rawheight=“1232” class=“origin_image zh-lightbox-thumb” width=“2090” data-original=“https://pic2.zhimg.com/80e327d62bf70d7661182d44d08c6c7e_r.jpg"&gt;

{kind=link}
{kind=link}
然后你也就可以对比**.当然,还有其它一些散乱的方法,比如stackoverflow, Quora, 知乎等依靠别人推荐,但是Google + GitHub **已经足够了。
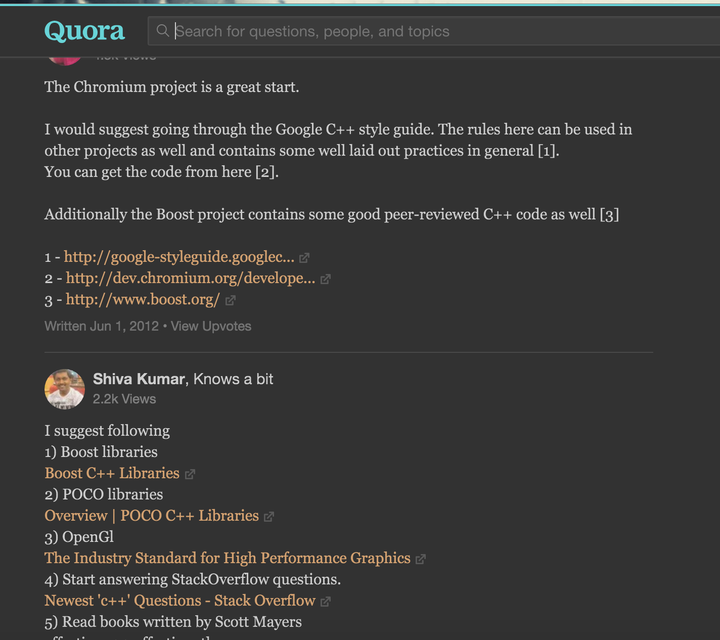
比如后面变的更厉害了,我还想继续研究一些有没有更好的C++代码以及项目,就可以直接Google
<img src=“https://pic2.zhimg.com/50/065be11595c7cce9d7daedc2626b2dc6_hd.jpg" data-rawwidth=“1492” data-rawheight=“1068” class=“origin_image zh-lightbox-thumb” width=“1492” data-original=“https://pic2.zhimg.com/065be11595c7cce9d7daedc2626b2dc6_r.jpg"&gt;

{kind=link}
{kind=link}
然后点开一个
<img src=“https://pic2.zhimg.com/50/47356299bd99a4375806681d7255053a_hd.jpg" data-rawwidth=“1432” data-rawheight=“998” class=“origin_image zh-lightbox-thumb” width=“1432” data-original=“https://pic2.zhimg.com/47356299bd99a4375806681d7255053a_r.jpg"&gt;

{kind=link}
{kind=link}
这里面虽然是重复问题,但是对你是很好的,要一一点开,发现每一个好的地方。
<img src=“https://pic3.zhimg.com/50/90602546a337c1bcc8a4adf0b8567672_hd.jpg" data-rawwidth=“1424” data-rawheight=“1266” class=“origin_image zh-lightbox-thumb” width=“1424” data-original=“https://pic3.zhimg.com/90602546a337c1bcc8a4adf0b8567672_r.jpg"&gt;

{kind=link}
{kind=link}
c++11 wikipedia
写点代码实验实验 C++ Primer Effective modern C++ CMake The Definitive Guide to GCC
专门讲解gcc各种flag。不过我觉得初学者真的用得到那么多选项吗。。
GCC Compiler Options这样的东西,应该做的就是去记住一些常用选项,然后了解它分哪几类,后面去查好了,不用系统的去学。 https://gcc.gnu.org/onlinedocs/gcc/
g++ GDB
**#include
// 你可以去研究C++11的标准库源码。 写正则引擎
算法
网络
HTTP
什么才算是会http的标准呢。。
简单的说起,http状态码得知道吧?包长啥样得知道吧?常见的几个http参数得知道吧?一次请求都干了些啥得知道吧?无状态的链接表述得知道吧?cookie怎么工作得知道吧?session如何实现得知道吧?POST表单的几种表述得知道吧?mime得知道那么点吧?XMLHttpRequest干了啥得知道吧?协议提升是个什么事得知道吧?长链接是啥得知道吧……总的来说,不求通读http标准,至少清楚它能干啥不能干啥,关键部分怎么实现如何解析,这些都要有个明确的印象。
操作系统
数据库
redis
redis
string: get(name) Return the value at key name, or None if the key doesn’t exist getrange(key, start, end) Returns the substring of the string value stored at key, determined by the offsets start and end (both are inclusive) getset(name, value) Sets the value at key name to value and returns the old value at key name atomically.
安全
编译器
去Coursera上报Stanford的编译课,跟着学。别自己看龙书。
不过如果时间有限,不想像本科生上课那样学习而是想快速获得一些编译原理的感觉的话,看看LLVM Tutorial: Table of Contents,跟着把东西做出来就行了。另外还有图灵社区 : 图书 : 两周自制脚本语言和图灵社区 : 图书 : 自制编程语言,适合想玩票的看看(不过我挺不喜欢日本人的行文风格。。)
人工智能
Deep Learning
interview
深度学习面试题
一些面试的建议: 1:bat三家都喜欢问大量的计算机基础知识,考察工程能力,b都喜欢问数据结构和leetcode,t问的比较随意但是很考察思维能力;(当然还是得看面试官)
2:对于像我这种非计算机班科出身的(数学统计),面机器学习算法的公司比较容易,面工程的公司比较难;
3:深度学习入门门槛很低,但是精通门槛很高,仍然很多东西都是黑盒子,因此如果真的没有这方面经验,不建议写进简历,很容易被问倒;面试官如果自身不精通,他压根不会问深度学习,如果问了,那他基本上还是比较懂行的;(个人经验,不一定准)
4:面试有些问题不确定,就说自己知道的,知道多少说多少,反正不能什么都不说;
我最近换工作,基本上轮了一圈大的互联网公司,下面是我的面经,希望对nlp或者机器学习深度学习感兴趣的朋友准备面试有点帮助,有些问题我答得不准希望不吝赐教;
— 某新闻app — round1:
1:cnn做卷积的运算时间复杂度;
2;Random forest和GBT描述;
3:(看到kaggle项目经历)为什么xgboost效果好?
4:leetcode;
round2:
1:工程背景;
2: python熟悉程度;
3:leetcode;
round3:
1:项目介绍
2:项目最难的是什么
3:项目做的最有成就感的是什么
4:生活做的最有成就感的是什么
5:一天刷多少次我们的app
不评论;
— 打车公司 — 1: LSTM结构推导,为什么比RNN好?
需要说明一下LSTM的结构,input forget gate, cell information hidden information这些,之前我答的是防止梯度消失爆炸,知友指正,不能防止爆炸,很有道理,感谢;
2:梯度消失爆炸为什么?
答案:略
3:为什么你用的autoencoder比LSTM好?
答案:我说主要还是随机化word embedding的问题,autoencoder的句子表示方法是词袋方法,虽然丢失顺序但是保留物理意义;(?)
4: overfitting怎么解决:
答案:dropout, regularization, batch normalizatin;
5:dropout为什么解决overfitting,L1和L2 regularization原理,为什么L1 regularization可以使参数优化到0, batch normalizatin为什么可以防止梯度消失爆炸;
答案:略
6: 模型欠拟合的解决方法:
答案:我就说到了curriculum learning里面的sample reweight和增加模型复杂度;还有一些特征工程;然后问了常用的特征工程的方法;
7:(简历里面写了VAE和GAN还有RL,牛逼吹大了)VAE和GAN的共同点是什么,解释一下GAN或者强化学习如何引用到你工作里面的;
答案:略
传统机器学习
1:SVM的dual problem推导;
2:random forest的算法描述+bias和variance的分解公式;
3:HMM和CRF的本质区别;
4:频率学派和贝叶斯派的本质区别;
5:常用的优化方法;
6: 矩阵行列式的物理意义(行列式就是矩阵对应的线性变换对空间的拉伸程度的度量,或者说物体经过变换前后的体积比)
7: 动态预测每个区域的用车需求量;
对于打车公司,我的感觉很好,hr态度和面试官态度都很好,包括最后跟老大打完电话约去公司聊一下确定一下;全程hr都是有问必答;
有一次为了去前面那个新闻app,而改了打车公司面试时间,hr态度都很好;
最后我已经决定了去深圳,不能去打车公司也有点遗憾了;
而且打车公司问的问题很专业,全程下来都是ML算法,不考脑残的leetcode;我根本没时间也不想再去刷leetcode就为了个面试;
— 手机公司 — round1:
1:LSTM相关的问题;
2:python写k-means;
3:想不起来了
round2:
1:业务相关的问题
2:leetcode 3:具体业务问题,也就是如何量化句子之间的相似度;
round3:
1:记不起来了
手机公司最近在搞发布会,面试过了一个星期再通知我去复面,我果断拒绝;
全程深度学习的东西基本上不问,问了一两个看来他们基本不用,然后就是leetcode;
手机公司做智能家居蛮有前途的;面试官态度很好;
— 搜索公司 — 三轮
1:怎么样识别文本垃圾信息;
2:(数据结构)树合并;
3:工作涉及到的业务知识;
4: python如何把16位进制的数转换成2进制的数;
5:MySQL的键的一个问题;
6: linux下如何把两个文件按照列合并
7:map-reduce的原理(问的基础,因为我简历没有mapreduce);
8:NLP方面的想法;
9:职业规划,专家型还是领导型;
10:如果给offer是不是直接来此公司;
说实话,搜索公司最耿直,一下午面玩完全没有任何磨磨唧唧就给了口头offer;
如果留在北京,首选肯定是它了;
后面问我在面其他哪些公司,如果给了offer去哪家,我说就这家,那时候也没想到后面的两家深圳公司也过了,感觉蛮愧疚的,就冲这个态度也应该去此公司的;
真的不像网上流传的那些;而且此公司最后面的manager是我见过态度很好而且感觉可以依靠人;
– 大厂 — 1: 链表逆转
2:1亿的文本如何放在100台机器上两两做相似度计算
3:40亿数据如何用2G内存排序
4;遍历树
5:HMM原理
大厂来面我的人级别很高,全程碾压我,最后我说话都不利索了,完全想不到会过的;
感觉大厂效率很高,hr也很专业;其实就面了两轮就谈薪资了;
总体来说,面试还是很顺利,基本上投的公司都给了offer;因为要去深圳,有两个很好的北京的机会不能去,真心遗憾;
更新几个面试被问到或者联想出来的问题,后面有时间回答
- SGD 中 S(stochastic)代表什么
- 个人理解差不多就是Full-Batch和Mini-Batch
- 监督学习/迁移学习/半监督学习/弱监督学习/非监督学习?
- Softmax Loss推一下
-----------------------------------------
本笔记主要问题来自以下两个问题,后续会加上我自己面试过程中遇到的问题。
深度学习相关的职位面试时一般会问什么?会问一些传统的机器学习算法吗?
如果你是面试官,你怎么去判断一个面试者的深度学习水平?
以下问题来自@Naiyan Wang
- CNN最成功的应用是在CV,那为什么NLP和Speech的很多问题也可以用CNN解出来?为什么AlphaGo里也用了CNN?这几个不相关的问题的相似性在哪里?CNN通过什么手段抓住了这个共性?
- Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
- Learn TensorFlow and deep learning, without a Ph.D.
- The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
- 以上几个不相关问题的相关性在于,都存在局部与整体的关系,由低层次的特征经过组合,组成高层次的特征,并且得到不同特征之间的空间相关性。如下图:低层次的直线/曲线等特征,组合成为不同的形状,最后得到汽车的表示。

*
* CNN抓住此共性的手段主要有四个:局部连接/权值共享/池化操作/多层次结构。
* 局部连接使网络可以提取数据的局部特征;权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者语音/文本) 中进行卷积;池化操作与多层次结构一起,实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。如下图:

*
* 上图中,如果每一个点的处理使用相同的Filter,则为全卷积,如果使用不同的Filter,则为Local-Conv。
- 为什么很多做人脸的Paper会最后加入一个Local Connected Conv?
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification
- 以FaceBook DeepFace 为例:

*
* DeepFace 先进行了两次全卷积+一次池化,提取了低层次的边缘/纹理等特征。
* 后接了3个Local-Conv层,这里是用Local-Conv的原因是,人脸在不同的区域存在不同的特征(眼睛/鼻子/嘴的分布位置相对固定),当不存在全局的局部特征分布时,Local-Conv更适合特征的提取。
以下问题来自@抽象猴
- 什麽样的资料集不适合用深度学习?
- 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势。
- 数据集没有局部相关特性,目前深度学习表现比较好的领域主要是图像/语音/自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成物体,语音信号中音位组合成单词,文本数据中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。对于没有这样的局部相关性的数据集,不适于使用深度学习算法进行处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
- 对所有优化问题来说, 有没有可能找到比現在已知算法更好的算法?
- 机器学习-周志华
- 没有免费的午餐定理:

*
* 对于训练样本(黑点),不同的算法A/B在不同的测试样本(白点)中有不同的表现,这表示:对于一个学习算法A,若它在某些问题上比学习算法 B更好,则必然存在一些问题,在那里B比A好。
* 也就是说:对于所有问题,无论学习算法A多聪明,学习算法 B多笨拙,它们的期望性能相同。
* 但是:没有免费午餐定力假设所有问题出现几率相同,实际应用中,不同的场景,会有不同的问题分布,所以,在优化算法时,针对具体问题进行分析,是算法优化的核心所在。
- 用贝叶斯机率说明Dropout的原理
- Dropout as a Bayesian Approximation: Insights and Applications
- 何为共线性, 跟过拟合有啥关联?
- Multicollinearity-Wikipedia
- 共线性:多变量线性回归中,变量之间由于存在高度相关关系而使回归估计不准确。
- 共线性会造成冗余,导致过拟合。
- 解决方法:排除变量的相关性/加入权重正则。
- 说明如何用支持向量机实现深度学习(列出相关数学公式)
- 这个不太会,最近问一下老师。
- 广义线性模型是怎被应用在深度学习中?
- A Statistical View of Deep Learning (I): Recursive GLMs
- 深度学习从统计学角度,可以看做递归的广义线性模型。
- 广义线性模型相对于经典的线性模型(y=wx+b),核心在于引入了连接函数g(.),形式变为:y=g−1(wx+b)。
- 深度学习时递归的广义线性模型,神经元的激活函数,即为广义线性模型的链接函数。逻辑回归(广义线性模型的一种)的Logistic函数即为神经元激活函数中的Sigmoid函数,很多类似的方法在统计学和神经网络中的名称不一样,容易引起初学者(这里主要指我)的困惑。下图是一个对照表:

*
*
- 什麽造成梯度消失问题? 推导一下
- Yes you should understand backdrop-Andrej Karpathy
- How does the ReLu solve the vanishing gradient problem?
- 神经网络的训练中,通过改变神经元的权重,使网络的输出值尽可能逼近标签以降低误差值,训练普遍使用BP算法,核心思想是,计算出输出与标签间的损失函数值,然后计算其相对于每个神经元的梯度,进行权值的迭代。
- 梯度消失会造成权值更新缓慢,模型训练难度增加。造成梯度消失的一个原因是,许多激活函数将输出值挤压在很小的区间内,在激活函数两端较大范围的定义域内梯度为0。造成学习停止

*
以下问题来自匿名用户
- Weights Initialization. 不同的方式,造成的后果。为什么会造成这样的结果。
- 几种主要的权值初始化方法:** lecun_uniform / glorot_normal / he_normal / batch_normal**
- **lecun_uniform:**Efficient BackProp
- glorot_normal:Understanding the difficulty of training deep feedforward neural networks
- he_normal:Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
- batch_normal:Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 为什么网络够深(Neurons 足够多)的时候,总是可以避开较差Local Optima?
- The Loss Surfaces of Multilayer Networks
- Loss. 有哪些定义方式(基于什么?), 有哪些优化方式,怎么优化,各自的好处,以及解释。
- Cross-Entropy / MSE / K-L散度
- Dropout。 怎么做,有什么用处,解释。
- How does the dropout method work in deep learning?
- Improving neural networks by preventing co-adaptation of feature detectors
- An empirical analysis of dropout in piecewise linear networks
- Activation Function. 选用什么,有什么好处,为什么会有这样的好处。
- 几种主要的激活函数:Sigmond / ReLU /PReLU
- Deep Sparse Rectifier Neural Networks
- Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
作者:竹间智能 Emotibot 链接:https://www.zhihu.com/question/41233373/answer/170708156 来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
冒着听起来过分自大的风险,我想分享一下我们关心的一些问题:
-
在使用一种方法(无论是深度学习或是**“传统”**方法)的时候,面试者对它的优点和局限性是否都有所认识。在面对不同的问题的时候,我们希望面试者可以通过独立思考做出一个informed choice,而不是因为“上周看了一篇paper是这样做的”或者“BAT/FLAG就是这样做的”。
-
面试者是否有完整的机器学习项目经验。这意味着从理解需求开始,到收集数据、分析数据,确定学习目标,选择算法、实现、测试并且改进的完整流程。因为我们希望面试者对于机器学习在实际业务中所带来的影响有正确的判断能力。当然,如果是可以通过python/或是结合Java/Scala来完成所有这些事情就更好啦。
-
面试者是否具备基本的概率/统计/线性代数的知识——数学期望,CLT,Markov Chain,normal/student’s t distribution(只是一些例子),或是PCA/SVD这些很基础的东西。另外(最理想的),希望面试者对于高维空间的一些特性有直觉上的认识。这部分并不是强行要求背公式,只要有理解就可以。毕竟这不是在面试数学系的教职——我们只是希望面试者可以较好地理解论文中的算法,并且正确地实现、最好可以做出改进;另外,在深度学习的调参过程中,比较好的数学sense会有助于理解不同的超参数对于结果的影响。
-
面试者是否有比较好的编程能力,代码习惯和对计算效率的分析能力(这个一般会按照最基本的算法工程师的要求来看,从略)
-
面试者在机器学习方面,对基本的概念是否有所了解(譬如说,线性回归对于数据的假设是怎样的),以及对于常见的问题有一定的诊断能力(如果训练集的正确率一直上不去,可能会出现哪些问题——在这里,我们希望面试者能够就实际情况,做一些合理的假设,然后将主要的思考逻辑描述清楚)。我们会根据面试者所掌握的方法再比较深入地问一些问题,而且我们希望面试者不仅仅是背了一些公式/算法,或是在博客/知乎上看到了一些名词(比如VC维度,KKT条件,KL divergence),实际上却不理解背后的理论基础(有时候这些问题确实很难,但**“知道自己不知道”和“不知道自己不知道”**是差别很大的)。打个比方,如果面试者提到核技巧,那么给到一个实际的线性不可分的数据(譬如XOR,或者Swiss Roll),面试者能清楚地设计,并通过实际计算证明某个kernel可以将此数据转化到一个高维并线性可分的空间吗?
-
在深度学习方面,我们希望面试者具备神经网络的基础知识(BP),以及常见的目标函数,激活函数和优化算法。在此基础上,对于常见的CNN/RNN网络,我们当然希望面试者能够理解它们各自的参数代表什么,比较好的初始参数,BP的计算,以及常见超参数的调整策略——这些相信Ian Goodfellow的Deep Learning一书都有非常好的介绍——我们也希望面试者能够在具体领域有利用流行框架(我们主要用tensorflow——但是这并不是必须的)搭建实际应用的经验。当然,我们希望面试者读过本领域的paper,并且手动验证过他们的想法,并且可以对他们方法的优缺点进行分析。当然,如果面试者有更多兴趣,我们可以探讨更深入的一些问题,比如如何避免陷入鞍点,比如通过引入随机噪音来避免过拟合,比如CNN的参数压缩,比如RNN对于动力系统的建模,比如基于信息理论的模型解释,等等等等,在这些方面,我们是抱着与面试者互相切磋的心态的。
-
通常上面我们说的都是监督学习,往往结果是回归或分类。当然,也许面试者还精通RL/transfer learning/unsupervised learning这些内容,那么我们可以逐一讨论。
此外,如果面试者应聘的是某一个特定领域的职位,那么当然地,我们会希望他同时具备很强的领域知识,这里就不展开说明了。
在很短的时间内想要全面地了解一个人确实非常困难。调查显示,往往面试官自以为很准的**“感觉”,其实是一个糟糕的performance predictor**。我希望可以结合相对客观的基础问题,以及面试者自身的特长,来对面试者的理论和实战能力做一个判断。基础扎实,有实战经验并且有一技之长的面试者通常会是非常理想的候选人。
最后的一点小tip,我真诚地希望面试者对问题有自己的思考和理解、有自己的体系,argument都是能够自洽的。坚持自己的观点并与面试官争论,远远好过为了刷面试而去背诵所谓标准答案(或者来知乎上找面试tips)。
比如过拟合怎么办这个问题,第一种你回答了drop out,data augmentation , weight decay。面试官就觉得你还不错了,但是第二种会接着这个问题,如果你讲了weight decay,立马问你常用的weight decay有哪些?怎么处理weight decay的权重。
如果你讲了L1,L2。让你比较为什么要两种weight decay,区别在哪里。比如如果你讲L1零点不可导才用L2,那么立马问你SMOOTHL1。
如果你都说明白了,就问你为什么weight decay能够一定程度解决过拟合?如果你说到了L0和稀疏性。接着就来问你为什么稀疏性有效?
作者:匿名用户
链接:https://www.zhihu.com/question/41233373/answer/154948147 来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
同样,让你对比新旧方案,比如有大部分人觉得基本RNN就是没有LSTM好,这么直接的答肯定不对的。就比如首先问你觉得LSTM解决RNN的梯度消失问题了吗?
这个回答要针对LSTM版本以及看面试官想听哪种,笼统来说,如果你回答很大程度解决了,接着就问如何解决的。如果你回答CEC的vanilla版本的LSTM通过加法修正而不同于RNN连乘。那么面试官追问遗忘门是不是连乘,是否带来梯度消失?
如果面试官问到这一步,你肯定要修正答案了,现在回答应该是:带遗忘门的LSTM没有本质解决RNN的梯度消失,
这个时候你再对LSTM和RNN进行优劣分析就知道LSTM实际上不同于RNN,后者把信息分配与‘过往’如何对当下造成影响都用一个W权重表示。而LSTM则通过遗忘门Wf专注把信息trap进来,仍通过另一个Wi去表示‘过往’对当下造成的影响。
很显然这里RNN就少用了一部分权重来建模这个问题。如果要解决的问题中用LSTM解决,遗忘门训练出来的理想状态是失效(全部忘记)的话,那么RNN方法肯定要优于LSTM的。
包括对比DL方法和传统ML方法。一定要深谙两种方法具体特点才能答出各自优劣,最终面试官很可能在考验你有没有‘天下没有免费的午餐’这种思想。
最有鉴别度也最实用: 什麽样的资料集不适合用深度学习?什麽造成梯度消失问题? 推导一下
仍旧以NLP举例,分词你用过多少种,他们之间的细微不同你是否都看过,是否追到源码中去?是否改过源码?这些都是层次递进的。分词只是其中很小一部分,但是非常基础的一部分,能体现你的团队在NLP领域的深入程度,基本上做了一年的NLP都不可避免的修改分词这个基本组件的源码。再考察一些相对新的东西认知到什么程度,比如word2vec,比如cnn提取文本信息。接着看你基础算法掌握的如何,比如说说PCA,SVM的原理,一些聚类算法的原理(不要求你写出公式,我也记不住)。这个阶段我问的任何一点都是工作中实际在用的,没有任何一条是为了问你而问,或为了显摆我会而你不会,请面试者摆正心态,好好的回答问题,不知道就说不知道!
作者:山同气
链接:https://www.zhihu.com/question/41233373/answer/145657844 来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1、手推bp 2、梯度消失/爆炸原因,以及解决方法
3、bn的原理,与
master path
I am currently learning deep learning as well. I set up a 1-year plan for myself. I have implemented this plan for almost 1 month and a half. I would like to share my experience as well as my background with you so that you can pick some tips that fit your current state. As a beginner, I have statistics and finance backgrounds. I have learned and used python for about 1–2 years. No professional training in either CS or ML area. In short, my learning plan covers: reading, coding practice, lecturing as well as projects. My main focus is to implement neural networks in tensorflow.
- I read < Deep Learning> written by Ian Goodfellow,
Yoshua Bengio and Aaron Courville every day for 2 hours at least.
- I also highly recommend some online courses like cs231n and cs224n from Stanford to start with.
- As for coding part, I start with some simple tasks like linear regression and logistic regression. Make sure you get familiar with the basic concepts like the placeholder, various cost function, and optimizers etc in a practical way.
- I found it is very useful to start coding neural networks with numpy since most tensorflow operations could be rewritten in numpy as well.
- I also set up the time to learn different types of neural networks(their definition and applications) and then give a lecture every night to review what I have learned.
- On the weekend, I download datasets from Kaggle or use Twitter API to do some text or sentiment analysis(since NLP is my main focus as well) with the neural network to test what I have learned during the weekdays.
Right now, I can build basic deep neural nets, word embedding like word2vec and doc2vec(+visualize the embedding with tensorboard), and recurrent neural networks by myself. Also, I have finished 5 chapters of
master path
(This post will be renewed to add new information from time to time)
My two cents.
Note I tried all of the resources I am going to recommend to you in the steps, and all of them are free (Renewed in Jan 2017 with a small portion that are not free, but they are clearly marked in italics bold text “not free”):
step 1 (basics), Coursera
- where you learn the basics : linear, logistic, neural network, recommendation system, PCA, KMeans, Anomaly detection. etc.
- What it did not cover but a real machine learning scientist/engineer still need to know about: math behind backpropogation, CNN, RNN/LSTM/GRU, and many other stuff in statistics (refer to step 3).
- link: Machine Learning - Stanford University | Coursera
step 2 (CNN), CS231n by Standford FeiFeiLi. This is not really online MOOC like EDX or Coursera, but you can access all the slides, videos and codes.
- It covers CNN very well. Also it covers RNN.
- Link: CS231n: Convolutional Neural Networks for Visual Recognition
step 3 (statistics), Highly recommend ! Harvard cs109 for data science. It covers a lot of important statistics knowledge for machine learning and data science. Further, it provides very good API and shows how to use the packages ,e.g., to plot pretty figures. Note : This course uses sklearn as its statistics/machine_learning tool. As far as I know, cs109 did not cover other machine learning tools such as Keras or Tensorflow very much as for 2016. Their latest homework solutions are not public. Only the past homework solutions are public, such as 2014, 2015. link: CS109 Data Science
step 4 (tensorflow), Udacity MOOC machine learning It covers CNN, RNN/LSTM, and word2vec very well, especially in tensorflow. You have to be familiar with at least one of these machine learning tools: Tensorflow, Caffe, Keras, Torch, Theano, …. Which are most important ? My personal opinion is : Keras , Tensorflow. Deep Learning | Udacity
Step 5 (Geoffrey Hinton !), if you have more time and want to learn machine learning in the hard way and know deeply, try Hinton’s Coursera. You might be stuck a lot, but working through this course is really worth it. It is worth to mention that some stuff in this course has been a little bit outdated. For example, Restricted Boltzmann Machine (though I love it a lot and I trust it will find its new value in future) is not as popular as 10 years ago in some certain areas, e.g., image recognition where CNN+ReLu is better. link : Neural Networks for Machine Learning - University of Toronto | Coursera
Step6 (Kaggle, etc), many other useful resources, such as Kaggle projects, blogs, individuals’ githubs, meet-ups in your city are very useful as well ….. However, they would make more sense after you have grabbed the basics, which are fully covered by the above 5 steps. Example link: rasbt/python-machine-learning-book , Kernels | Kaggle
Step 7, CS224d (RNN, NLP) : This course explains word2vec and LSTM/GRU very well. I have not finished it yet… So far I only finished Notes 1~5. The rest e.g., Dynamic CNN has not been read yet. — Feb. 2017. https://cs224d.stanford.edu
Oxford: Natural Language Processing with Deep Learning • /r/CS224n`
**Tools **for Machine learning or/and Data science (1) tensorlfow playground
Tensorflow — Neural Network Playground is very simple and straightforward to play with different models : linear , logistic, neural networks. It helps us to quickly test the how different set up of regularization, learning rate, activation and feature can affect the result. (2) Keras
Keras Documentation Keras is very popular and is built upon tensorflow. Usually for starters, getting familiar with Keras will make Tensorflow make more sense. Keras is alike ‘wrapped up’ version of Tensorlfow or a higher level of Tensorflow. There are many examples of Keras on Kaggle, e.g., Digit Recognizer | Kaggle (I randomly picked up this example) (3) sklearn
This is a package that can be used with Python. It is most popular in data science. Actually it can be learnt by following Harvard cs109 mentioned in Step 3, which majorly uses sklearn as machine learning package (as far as I know, cs109 until 2015 did not cover Keras or Tensorflow. I have not fully tried cs109 2016 yet) Official website Link : scikit-learn: machine learning in Python
(4) Tensorflow
The above “step 4” , Udacity course, is a good tutorial of Tensorflow for beginners. Official website Link: TensorFlow , TensorFlow中文社区-首页 (Chinese version. Basically everything has been translated into Chinese by volunteers.)
**Programming **: I only recommend Python and R. My personal opinion is that Python first priority. Refer to : http://blog.codeeval.com/codeeva… and Most Popular Coding Languages of 2016
C/C++ and Java are always useful of course, but the trend for machine learning and data science is Python and R (controversial opinion :)
Python or R ?
Please browse this Which is better for data analysis: R or Python? Is R still a better data analysis language than Python? Has anyone else used Python with Pandas, to a large extent, in data analysis projects?
The short answer (alter: contentious ! people have different opinions !) is : Python is more important than R. Courses for Python and R: Python:
The first two items below are good for starters to get familiar with Python:
- Codecademy Catalog offers free Python on-line tutorial with IDE and demos.
- Python Numpy Tutorial is a short version of Python tutorial, also it includes basics usage of numpy, scipy, matplotlib packages.
- ***not free: ***“learn Python the hard way” Learn Python the Hard Way
- Some packages used with Python are very popular, and CS109 covers most of them. Also, their cheatsheet can be useful. Just google “package_name, cheatsheet”, example: Python Cheat Sheets - Google Drive
R
*I myself have not spent much time on R yet, and I should not recommend anything … *Having said that:
- Coursera : I only quickly browsed the R course on Coursera, and it’s OK to me to follow. More reviews, refer to How is the Coursera R programming course by Johns Hopkins? .
- DataCamp : Not 100% free: I also tried the “introduction” and “intermediate” R course of “Learn R, Python & Data Science Online | DataCamp” . It is only free of its “introduction to R”. The course is easy to follow, and it allows me to get the grammar, syntax and basics of R very quickly.
- Some people recommend Hands-On Programming with R . I have not tried it yet.
Other related courses :
Preparing for Insight
Preparing for the Transition to Data Science
Advanced : more and deeper knowledge related to ML, statistics
- Hidden Markov Model (HMM)
- Conditional Random Field
- Generative model, discriminative model
- Statistics (CS109 covers basic statistics for data science. However, for machine learning scientists or researchers, more statistics such as this book http://statweb.stanford.edu/~tib… would be useful — I have not read this book yet. )
- To be continued.
Big Data
大数据工程师的话,至少要熟悉storm, hadoop, spark之间优缺点,性能挑优,监控之类的,这块面比较广,各种开源的分布式系统多了解一下,kafka, elasticsearch, influxdb, fluentd之类的。当然,数据结构和算法也很重要。
大数据主要从侧重对数据的存储、分析,会涉及到分布式存储系统、分布式计算系统、机器学习、数据可视化等方面,每一个方面都可以深入学习很长时间
后台开发主要侧重网络编程、多线程/多进程调度、操作系统、各类数据库存取等,同样每一点都可以深挖
个人认为后台开发对网络编程、各类协议、web服务器设计扩展、中间件,消息系统,数据存取等有所要求。
做hdfs+spark日志处理,做做平台搭建和spark编程,但是都是python写的