Product Strategy
- Cost Strategy
- Differentiation Strategy
- Focus Strategy
- Quality Strategy
- Service Strategy
Credit Risk Management
Credit score
Credit scoring models (scorecards)
FICO (Fair Isaac Corporation) Scores
- 支付历史
- 信用利用率
- 信用记录
- 信用使用
- 新信贷
The overall FICO score range is between 300 and 850. In general, scores in the 670 to 739 range indicate a “good” credit history and most lenders will consider this score favorable. In contrast, borrowers in the 580 to 669 range may find it difficult to get financing at attractive rates.
| Credit Score | Description |
|---|---|
| 760 - 849 | Excellent |
| 700 - 759 | Great |
| 660 - 699 | Good |
| 620 - 659 | Average |
| 580 - 619 | Poor |
| below 579 | Very Poor |
VantageScore
- 高权重:付款历史
- 极端权重:年龄和信用类型
- 极端权重:信用利用率
- 中等权重:总余额
- 低权重:近期行为
- 极低权重:可用积分
Other Scores
Application Scoring
申请评分卡,用于信贷审批,用于贷前审批阶段对借款申请人的量化评估。
Behavior Scoring
行为评分卡,用于贷后管理,通过借款人的还款及交易行为,结合其他维度的数据预测借款人未来的还款能力和意愿。
Collection Scoring
催收评分卡,用于催收管理,在借款人当前还款状态为逾期的情况下,预测未来该笔贷款变为坏账的概率,由此衍生出滚动率、还款率、失联率等细分的模型。
Feature Selection
WOE(Weight of Evidence)
使用证据权重 (WoE) 方法转换所有自变量(如年龄、收入等)。该方法根据每个组级别的好申请人与差申请人的比例,衡量分组区分好坏风险的“强度”,并试图找到自变量与目标变量之间的单调关系。 $$ woe_i = ln(\frac{bad_i}{bad total} / \frac{good_i}{good total}), i=(1,2,…,10) $$ WOE 实际展现的是 “该分段下的好用户数和坏用户数的比值” 与 “好用户总数与坏用户总数的比值” 的差异。WOE 越大,差异越大,好用户的可能性越大。
同时 WOE 变换常应用于特征工程,当我们对某些特征变量进行等频或等距等分箱后发现,发现每级分段 WOE 不满足单调性时(大部分为离散型变量),进行 WOE 变换,即采用对应每分段的 WOE 值替换掉特征原始值,此时该特征的分布将会是单调的。
通过 WOE 变换,同时保持 WOE 曲线具备单调性,带来的好处在于特征值与 y 值具备正(负)相关性,例如我们定义坏用户为 1 时,特征值越大,预测为坏人的概率将越高。
IV(Information Value)
信息价值,它衡量自变量的预测能力,这对特征选择很有用。也就是说,当我们想要拿出证据证明“年龄”这个变量对于违约概率是否有影响的时候,可以使用这个指标评估年龄到底对违约概率的影响有多大。
| Information Value | Predictive Power |
|---|---|
| < 0.02 | Useless |
| 0.02 - 0.1 | Weak |
| 0.1 - 0.3 | Medium |
| 0.3 - 0.5 | Strong |
| > 0.5 | Suspiciously good; too good to be true |
Model evaluation
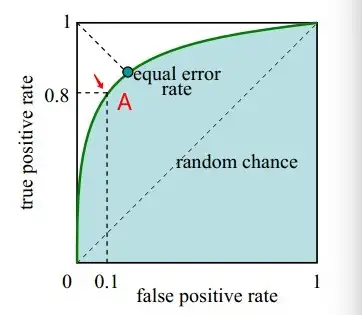
ROC (receiver operating characteristic) / AUC (area under curve)
一个越好的分类模型,ROC曲线越接近左上方,AUC也越来越接近1;反之,如果这个分类模型得出的结果基本上相当于随机猜测,那么画出的图像就很接近于左下角和右上角的对角线(random chance),那么这个模型也就没什么意义了。
衍生出几个重要的评价指标:
- 准确率(Accuracy Rate):(TP+TN)/N。
- 召回率(TPR,True Positive Rate):TP/(TP+FN)。在所有实际是正样本中有多少被正确识别为正样本。
- 误报率(FPR,False Positive Rate):FP/(FP+TN)。在所有实际为负样本中有多少被错误识别为正样本。
- 查准率(Precision Rate):TP/(TP+FP)。被识别成正样本的样本中有多少是真的正样本。
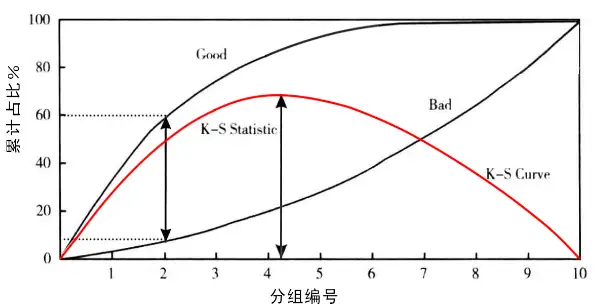
K-S (Kolmogorov-Smirnov)
作为一个模型,我们当然希望这个模型能够帮我们挑选到最多的好客户,同时不要放进来那么多坏客户。K-S值就是一个这样思路的指标。比如,在完成一个模型后,将测试模型的样本平均分成10组,以好样本占比降序从左到右进行排列,其中第一组的好样本占比最大,坏样本占比最小。这些组别的好坏样本占比进行累加后得到每一组对应的累计的占比。好坏样本的累计占比随着样本的累计而变化(图中Good/Bad两条曲线),而两者差异最大时就是我们要求的K-S值(图中比较长的直线箭头的那个位置)。
KS值的取值范围是[0,1]。通常来说,值越大,表明正负样本区分的程度越好。一般,KS值>0.2就可认为模型有比较好的预测准确性。(这个值有评论指出比较低,可能由于不同的场景和要求下不同,仅作为参考)
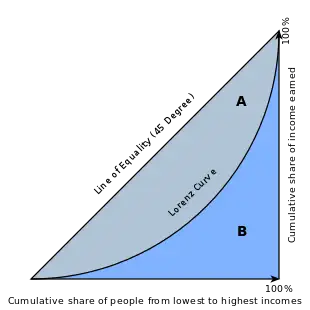
GINI
还记得经济学中那个著名的基尼系数吗?下图应该可以让你回忆起来。将一个国家所有的人口按最贫穷到最富有进行排列,随着人数的累计,这些人口所拥有的财富的比例也逐渐增加到100%,按这个方法得到图中的曲线,称为洛伦兹曲线。基尼系数就是图中A/B的比例。可以看到,假如这个国家最富有的那群人占据了越多的财富,贫富差距越大,那么洛伦茨曲线就会越弯曲,基尼系数就越大。
同样的,假设我们把100个人的信用评分按照从高到低进行排序,以横轴为累计人数比例,纵轴作为累计坏样本比例,随着累计人数比例的上升,累计坏样本的比例也在上升。如果这个评分的区分能力比较好,那么越大比例的坏样本会集中在越低的分数区间,整个图像形成一个凹下去的形状。所以洛伦兹曲线的弧度越大,基尼系数越大,这个模型区分好坏样本的能力就越强。
PSI(Population Stability Index)
PSI叫做群体稳定性指标,用于衡量两组样本的评分是否有显著差异。PSI = sum((实际占比-预期占比)*ln(实际占比/预期占比)
举个栗子,假设在训练一个评分模型时,我们将样本评分按从小到大排序分成10组,那么每组会有不同的样本数量占比P1;评分模型制作出来之后,我们试用这个模型去预测新的一组数据样本,按上面的方法同样按评分分成10组,每组也会有一定的样本数量占比P2。PSI可以帮助我们量化P1和P2,即预期占比与实际占比的差距。
这个指标同样也可以用于监测每月申请客户或成交客户的变化。
Credit Risk Strategies
-
最简单、最常见的信用风险策略形式是基于接受或拒绝决策的一维截止点。cut-off level(信用审批的最低分数)可以是一个固定值的硬 cut-off,也可以是可调整的值,具有多种处理方式,如无条件接受、有条件接受或拒绝。通常,贷方使用细分策略来识别跨客户群的不同截止水平;贷款人可以通过许多因素进行细分,包括区域、人口统计、渠道分布或以前拒绝的客户。截止水平取决于业务目标。
-
更复杂的信用风险策略有多个截止水平,或者结合两个或多个信用评分(例如内部申请评分和局评分)。通常,策略包括其他预测模型,如客户保留/响应率或客户生命周期价值。这些行为分数——结合政策和监管规则以及业务关键绩效指标 (KPI)——可以帮助组织利用预测分析和业务规则。
-
组织还可以使用基于风险的定价分数来调整利率、信用额度、还款期限等产品报价。基于风险的定价有多种形式:从基于损益分析的一维多截止处理(例如,接受下限),到结合两个维度的矩阵方法,例如行为评分和未偿余额来识别信用额度或利率。团队还可以采用矩阵方法进行简单的优化来控制运营成本。例如,结合两个预测模型——分数和响应率——可以帮助营销部门关注可能响应报价的低风险客户。
Reference
Credit Risk Management
Credit Scoring Series Part Five: Credit Scorecard Development
Credit Scoring Series Part Eight: Credit Risk Strategies
WOE, IV and Scorecards in Credit Risk Modelling
Credit Risk Management in Banking
A COMPLETE GUIDE TO CREDIT RISK MODELLING